

Python实现长度16位十进制整数的客制化雪花算法(Snowflake)生成器


前言
Javascript 整数表达最大为 2^53-1 位,大约是十进制16位,超过就会导致精度丢失,一般在浏览器中会直接报错。
场景
我们知道,雪花算法(SnowFlake)生成的雪花ID是 2^64 位,如果直接使用雪花算法(SnowFlake)生成器,前端是没办法直接拿到int类型的雪花ID,需要后端先将其转换为string类型才行。
使用雪花算法(SnowFlake)的很重要一个原因就是,int类型对数据库索引是很友好的,为了前后端数据交互方便,在数据库中直接储存string类型的雪花ID是让我无法接受的,那么摆在我面前我能想到的只有两个解决方案:
在每次向前端发送包含雪花ID数据时,先将雪花ID转换为string类型后再进行发送。
缩短雪花ID,使其不超过 2^53-1 位。
我选择第二个解决方案。
重新设计雪花算法
首先重新设计雪花ID:
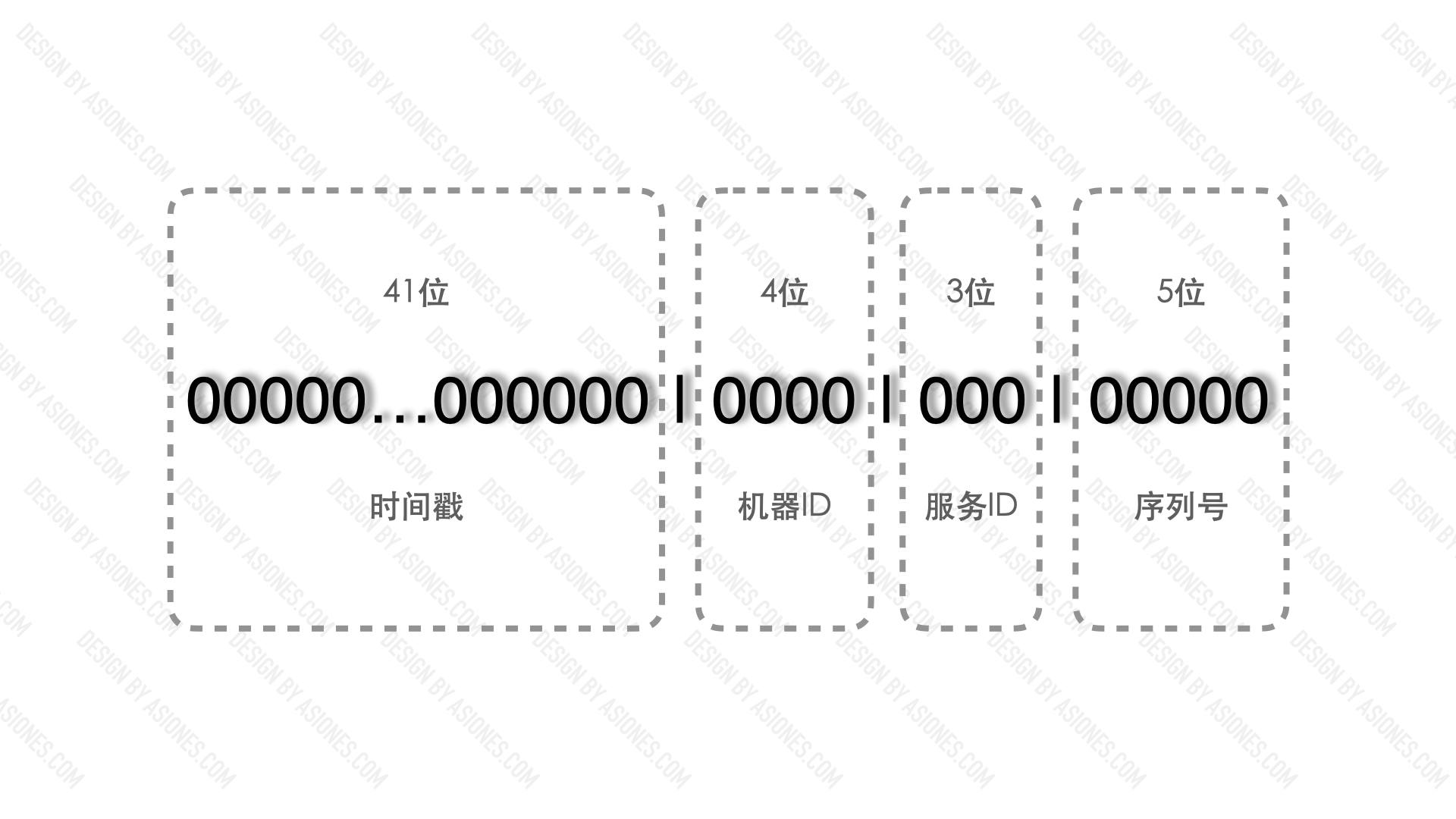
41位,时间戳,精确到毫秒,最大值为 2^41 ,一年有 3.1556926 × 1010 毫秒,2^41/3.1556926 × 1010 大约等于69年。
4位,我定义它4位来表示机器ID,最高可以容纳16台机器。由于是分布式,我们避免不了有很多机器,但在我的项目里,16台机器已经够用了。(当然,你可以让它为5位,6位……
3位,我定义它3位来表示服务ID,最高可以容纳8个服务。在我的项目里,不仅用户uid会使用到雪花ID,订单ID,流水号等都可能会使用到雪花算法来生成序列号。(当然,你可以让它为4位,5位……
5位,最大可容纳32个序列号,在同一机器同一服务同一毫秒内产生的ID通过该序号进行累加区分。
其实除了前41位时间戳,后面的12位均可以自定义,我的需求是这样,故我定义它为这样。
实现代码
import time
# 项目元年时间戳
START_TIMESTAMP = 166666666666
# 机器ID bit位数
MACHINE_ID_BITS = 4
# 服务ID bit位数
SERVICE_ID_BITS = 3
# 序号 bit位数
SEQUENCE_BITS = 5
# 机器ID最大值计算
MAX_MACHINE_ID = (1 << MACHINE_ID_BITS) - 1
# 服务ID最大值计算
MAX_SERVICE_ID = (1 << SERVICE_ID_BITS) - 1
# 序号掩码最大值
MAX_SEQUENCE = (1 << SEQUENCE_BITS) - 1
# 移位偏移值计算
SERVICE_ID_SHIFT = SEQUENCE_BITS
MACHINE_ID_SHIFT = SEQUENCE_BITS + SERVICE_ID_BITS
TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + SERVICE_ID_BITS + MACHINE_ID_BITS
class SnowFlake:
"""
用于生成IDs
"""
def __init__(self, machine_id, service_id, sequence=0):
"""
初始化
:param machine_id: 机器ID
:param service_id: 服务ID
:param sequence: 序号掩码
"""
# 校验机器ID
if machine_id > MAX_MACHINE_ID or machine_id < 0:
raise ValueError('机器ID值越界')
# 校验服务ID
if service_id > MAX_SERVICE_ID or service_id < 0:
raise ValueError('服务ID值越界')
self.machine_id = machine_id
self.service_id = service_id
self.sequence = sequence
self.last_timestamp = -1 # 上次计算的时间戳
def _gen_timestamp(self):
"""
生成整数时间戳
:return:int timestamp
"""
return int(time.time() * 1000)
def generate_id(self):
"""
生成ID
:return:int
"""
timestamp = self._gen_timestamp()
# 时钟回拨
if (self.last_timestamp - timestamp) > 3:
raise Exception('时钟回拨')
if self.last_timestamp > timestamp:
timestamp = self._til_next_millis(self.last_timestamp)
if timestamp == self.last_timestamp:
self.sequence = self.sequence + 1
if self.sequence > MAX_SEQUENCE:
timestamp = self._til_next_millis(self.last_timestamp)
self.sequence = 0
else:
self.sequence = 0
self.last_timestamp = timestamp
# 核心计算
new_id = ((timestamp - START_TIMESTAMP) << TIMESTAMP_LEFT_SHIFT) | (self.machine_id << MACHINE_ID_SHIFT) | \
(self.service_id << SERVICE_ID_SHIFT) | self.sequence
return new_id
def _til_next_millis(self, last_timestamp):
"""
等到下一毫秒
"""
timestamp = self._gen_timestamp()
while timestamp <= last_timestamp:
timestamp = self._gen_timestamp()
return timestamp
def parse_id(self, to_be_parsed_id: int):
"""
解析ID
"""
binary = bin(to_be_parsed_id)
sequence = int(binary[-SERVICE_ID_SHIFT:], 2)
service_id = int(binary[-MACHINE_ID_SHIFT:-SERVICE_ID_SHIFT], 2)
machine_id = int(binary[-TIMESTAMP_LEFT_SHIFT:-MACHINE_ID_SHIFT], 2)
timestamp = int(binary[:-TIMESTAMP_LEFT_SHIFT], 2) + START_TIMESTAMP
date_time = datetime.fromtimestamp(timestamp / 1000)
return {
"timestamp": date_time,
"machine_id": machine_id,
"service_id": service_id,
"sequence": sequence
}
if __name__ == '__main__':
GneSFID = SnowFlake(1, 1, 0)
start_timestamp = int(time.time() * 1000)
for i in range(1000000):
print(GneSFID.generate_id())
end_timestamp = int(time.time() * 1000)
waste_time = (end_timestamp - start_timestamp) / 1000
print(waste_time)
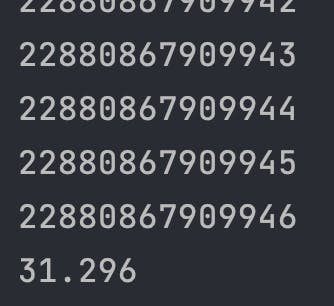
经测试,上面的雪花算法生成100w条雪花ID需要花费大约32s。每毫秒生成的ID 100w/(32*1000) 大约也是等于32,即序列号为32bit满载。
挖坑😅
最后,如果你的初始元年时间戳值离当前时间很近的话,会导致最后生成的雪花ID只有14或者15位,这是因为生成ID的时间戳与元年时间戳差值太小,在二进制中就表现为前面很多0,也就不起作用,同时也无法起到占位的作用。
为了统一长度,可以这样做,将长度不够16位的ID前面用0补充占位。
然后我就发现用 zfill() 补完0从str转为int后,0又消失不见了😵💫
更新:新增 parse_id() 解析ID方法
代码更新在了上面的实现代码。
该方法接收一个 to_be_parsed_id: int 参数,解析后返回一个 dict 。
方法使用示例:
# ...省略 class SnowFlake
if __name__ == '__main__':
GneSFID = SnowFlake(1, 1, 0)
for i in range(100000):
snow_id = GneSFID.generate_id()
print(snow_id, '-->', GenSFID.parse_id(snow_id))
如果这片文章对你有帮助的话,请给我点个赞吧👍🏼,就在你的屏幕右上方(手机底部)的😊按钮。